思爱普
爬虫
1024
vulnhub
慢速外设接口
计算机辅助药物设计
python教学
链表
STM32G070RBT6
软件
cnn
USB转JTAG
harbor
AI二次开发
ida
ChatGPT国内
文档管理
数据库通用命令
支持向量机
bug
attention
2024/4/12 3:40:08
36k字从Attention讲解Transformer及其在Vision中的应用(pytorch版)
文章目录 0.卷积操作1.注意力1.1 注意力概述(Attention)1.1.1 Encoder-Decoder1.1.2 查询、键和值1.1.3 注意力汇聚: Nadaraya-Watson 核回归1.2 注意力评分函数1.2.1 加性注意力1.2.2 缩放点积注意力1.3 自注意力(Self-Attention)1.3.1 自注意力的定义和计算1.3.2 自注意…

基于普通RNN、LSTM、加入atttention的LSTM的指代消解【代码在文末】
基于普通RNN、LSTM、加入atttention的LSTM的指代消解【代码在文末】 题目要求描述摘要1 指代消解简介2 RNN框图和机理分析3 LSTM框图和机理分析4 加入 atttention 的 LSTM框图和机理分析测试分析5 模型对比梯度分析RNN梯度分析LSTM梯度分析基于attention的LSTM梯度分析性能对比…

基于CNN-LSTM-Attention的时间序列回归预测matlab仿真
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1卷积神经网络(CNN)在时间序列中的应用
4.2 长短时记忆网络(LSTM)处理序列依赖关系
4.3 注意力机制(Attention)
5…
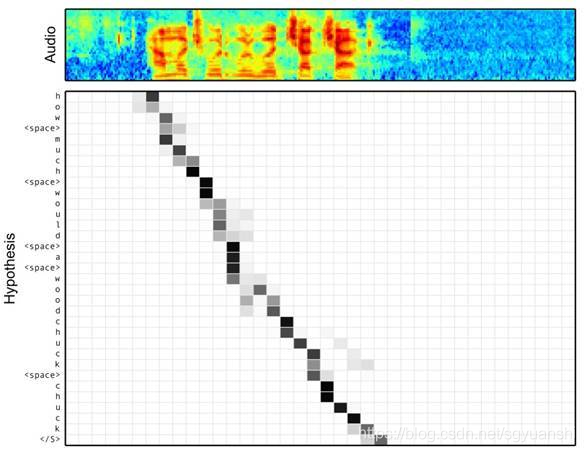
深度学习中的注意力机制(Attention)
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
…
光伏预测 | Matlab基于CNN-SE-Attention-ITCN的多特征变量光伏预测
光伏预测 | Matlab基于CNN-SE-Attention-ITCN的多特征变量光伏预测 目录 光伏预测 | Matlab基于CNN-SE-Attention-ITCN的多特征变量光伏预测预测效果基本描述模型简介程序设计参考资料 预测效果 基本描述 Matlab基于CNN-SE-Attention-ITCN的多特征变量光伏预测 运行环境: Matla…
论文阅读:An end-to-end spatio-temporal attention model for human action recognition from skeleton data
目录
创新点(Main Contributions)
Proposed Method
Spatial Attention
Temperal Attention
Joint Training of the Networks
Regularized Objective Function 论文名称:An end-to-end spatio-temporal attention model for human actio…
论文阅读:Adding Attentiveness to the Neurons in Recurrent Neural Networks
目录
Summary
Details (Implementation)
原来的 RNN 结构
变为 Element-wise-Attention Gate (EleAttG) 后 论文名称:Adding Attentiveness to the Neurons in Recurrent Neural Networks(2018 ECCV)
下载地址:https://arxiv…
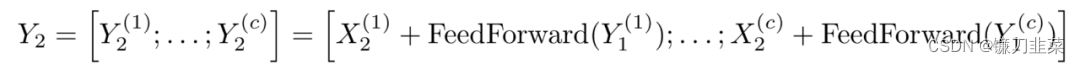
【NLP】手把手使用PyTorch实现Transformer以及Transformer-XL
手把手使用PyTorch实现Transformer以及Transformer-XL Abstract of Attention is all you need使用PyTorch实现Transformer1. 构建Encoder-Decoder模型1.1 导入依赖库1.2 创建Encoder-Decoder类1.3 创建Generator类 2. 构建Encoder2.1 定义复制模块的函数2.2 创建Encoder2.3 构…

从Attention到Bert——2 transformer解读
从Attention到Bert——1 Attention解读 从Attention到Bert——3 BERT解读
1 为何引入Transformer 论文:Attention Is All You Need Transformer是谷歌在2017年发布的一个用来替代RNN和CNN的新的网络结构,Transformer本质上就是一个Attention结构&#x…

分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】
分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】 目录 分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】分类效果基本描述模型描述程…
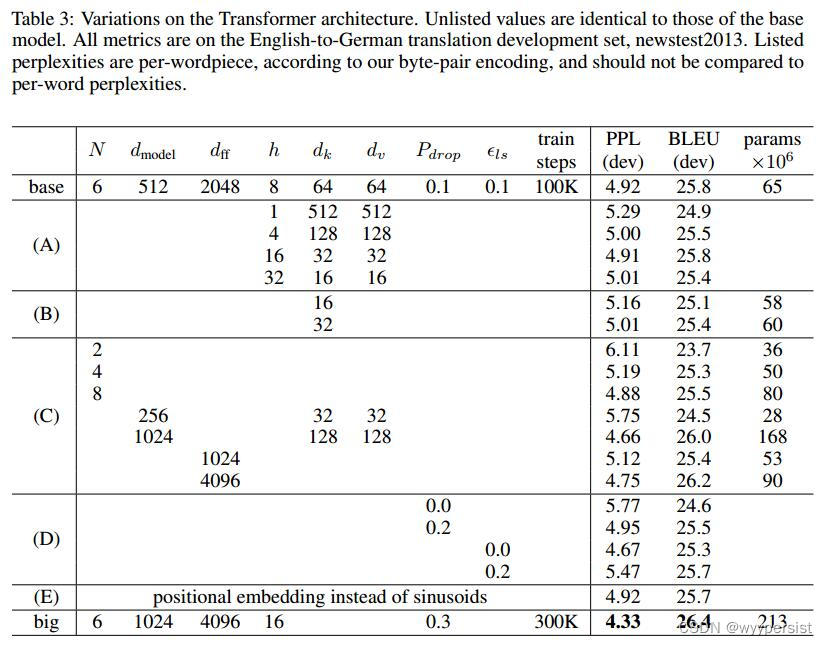
Transformer (Attention Is All You Need) 论文精读笔记
Transformer(Attention Is All You Need)
Attention Is All You Need
参考:跟李沐学AI-Transformer论文逐段精读【论文精读】
摘要(Abstract)
首先摘要说明:目前,主流的序列转录(序列转录:给…

时序预测 | MATLAB实现Attention-GRU时间序列预测(注意力机制融合门控循环单元,TPA-GRU)
时序预测 | MATLAB实现Attention-GRU时间序列预测----注意力机制融合门控循环单元,即TPA-GRU,时间注意力机制结合门控循环单元 目录 时序预测 | MATLAB实现Attention-GRU时间序列预测----注意力机制融合门控循环单元,即TPA-GRU,时…
机器学习:self-attention
输入 编码方式:
one-hot:word-embedding:能更明显的区分不同类别的输入 图也能看作是多个向量输入
输出
每个向量都有一个label 一整个sequence有一个label 模型自己决定有多少个label(sequence to sequence) 重点介绍每个vector有一个…
C刊级 | Matlab实现DBO-BiTCN-BiGRU-Attention蜣螂算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测
C刊级 | Matlab实现DBO-BiTCN-BiGRU-Attention蜣螂算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测 目录 C刊级 | Matlab实现DBO-BiTCN-BiGRU-Attention蜣螂算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测效果一览基本介绍模型描述程序…

分类预测 | Matlab实现CNN-GRU-Mutilhead-Attention卷积神经网络-门控循环单元融合多头注意力机制多特征分类预测
分类预测 | Matlab实现CNN-GRU-Mutilhead-Attention卷积神经网络-门控循环单元融合多头注意力机制多特征分类预测 目录 分类预测 | Matlab实现CNN-GRU-Mutilhead-Attention卷积神经网络-门控循环单元融合多头注意力机制多特征分类预测分类效果基本介绍模型描述程序设计参考资料…

多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本…

多维时序 | MATLAB实现RIME-CNN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现RIME-CNN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现RIME-CNN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现RIME-…
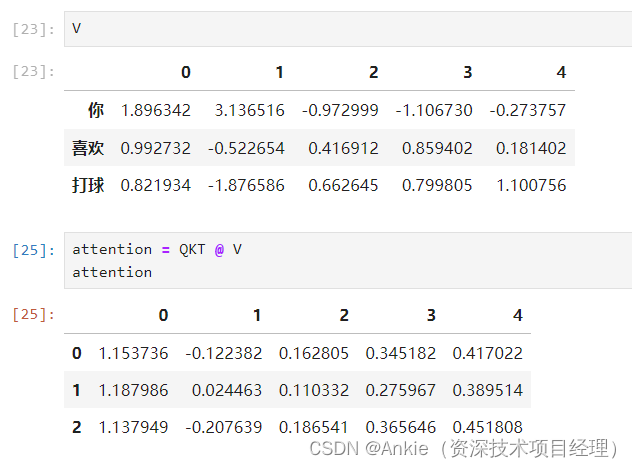
学习transformer模型-用jupyter演示逐步计算attention
学习transformer模型-用jupyter演示如何计算attention,不含multi-head attention,但包括权重矩阵W。
input embedding:文本嵌入
每个字符用长度为5的向量表示: 注意力公式: 1,准备Q K V: 先 生…

NLP:训练一个中文问答模型Ⅰ-Step by Step
训练一个中文问答模型I-Step by Step 本文基于经典的NMT架构(Seq2SeqAttention),训练了一个中文问答模型,把问题到答案之间的映射看作是问题到答案的翻译。基于Tensorflow 2.x实现,分词采用了jieba,在中文词汇粒度上训…

分类预测 | MATLAB实现WOA-CNN-BiLSTM-Attention数据分类预测
分类预测 | MATLAB实现WOA-CNN-BiLSTM-Attention数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-BiLSTM-Attention数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现WOA-CNN-BiLSTM-Attention数据分类预测,运行环境Matlab2023b及以上…

多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测
多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测,WOA-CNN-GR…

从Attention到Bert——1 Attention解读
下一篇从Attention到Bert——2 transformer解读 文章目录1 Attention的发展历史2015-2017年2 Attention的原理3 Multi-Head Attention4 Self-Attention为什么需要self-attention什么是self-attention5 Position Embedding最早,attention诞生于CV领域,真正…

多输入多输出 | MATLAB实现CNN-LSTM-Attention卷积神经网络-长短期记忆网络结合SE注意力机制的多输入多输出预测
多输入多输出 | MATLAB实现CNN-LSTM-Attention卷积神经网络-长短期记忆网络结合SE注意力机制的多输入多输出预测 目录 多输入多输出 | MATLAB实现CNN-LSTM-Attention卷积神经网络-长短期记忆网络结合SE注意力机制的多输入多输出预测预测效果基本介绍程序设计往期精彩参考资料 预…
时间序列 | MATLAB实现CNN-GRU-Attention时间序列预测
时间序列 | MATLAB实现CNN-GRU-Attention时间序列预测 目录时间序列 | MATLAB实现CNN-GRU-Attention时间序列预测预测效果基本介绍模型描述程序设计参考资料预测效果 基本介绍 MATLAB实现CNN-GRU-Attention时间序列预测,CNN-GRU结合注意力机制时间序列预测。 模型描…
【Machine Learning】Other Stuff
本笔记基于清华大学《机器学习》的课程讲义中有关机器学习的此前未提到的部分,基本为笔者在考试前一两天所作的Cheat Sheet。内容较多,并不详细,主要作为复习和记忆的资料。 Robust Machine Learning
Attack: PGD max δ ∈ Δ L o s s (…
分类预测 | MATLAB实现WOA-CNN-LSTM-Attention数据分类预测
分类预测 | MATLAB实现WOA-CNN-LSTM-Attention数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-LSTM-Attention数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现WOA-CNN-LSTM-Attention数据分类预测,运行环境Matlab2021b及以…
多维时序 | MATLAB实现SABO-CNN-GRU-Attention多变量时间序列预测
多维时序 | MATLAB实现SABO-CNN-GRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现SABO-CNN-GRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现SABO-CNN-GRU-Attention多变量时间序列预测。 模型描…
分类预测 | Matlab实现MTF-CNN-Mutilhead-Attention马尔可夫转移场卷积网络多头注意力机制多特征分类预测/故障识别
分类预测 | Matlab实现MTF-CNN-Mutilhead-Attention马尔可夫转移场卷积网络多头注意力机制多特征分类预测/故障识别 目录 分类预测 | Matlab实现MTF-CNN-Mutilhead-Attention马尔可夫转移场卷积网络多头注意力机制多特征分类预测/故障识别分类效果基本介绍模型描述程序设计参考…
多维时序 | MATLAB实现CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现CNN-BiGRU-Attention多变量时间序列预测,CNN-BiGRU-Attent…

基于Bert+Attention+LSTM智能校园知识图谱问答推荐系统——NLP自然语言处理算法应用(含Python全部工程源码及训练模型)+数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境服务器环境 模块实现1. 构造数据集2. 识别网络3. 命名实体纠错4. 检索问题类别5. 查询结果 系统测试1. 命名实体识别网络测试2. 知识图谱问答系统整体测试 工程源代码下载其它资料下载 前言
这个项目充分利用了…
多维时序 | MATLAB实现SSA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现SSA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现SSA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描述…
负荷预测 | Matlab基于TCN-BiGRU-Attention单输入单输出时间序列多步预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于TCN-BiGRU-Attention单输入单输出时间序列多步预测; 2.单变量时间序列数据集,采用前12个时刻预测未来96个时刻的数据; 3.excel数据方便替换,运行环境matlab…
分类预测 | Matlab实现GRU-Attention-Adaboost基于门控循环单元融合注意力机制的Adaboost数据分类预测/故障识别
分类预测 | Matlab实现GRU-Attention-Adaboost基于门控循环单元融合注意力机制的Adaboost数据分类预测/故障识别 目录 分类预测 | Matlab实现GRU-Attention-Adaboost基于门控循环单元融合注意力机制的Adaboost数据分类预测/故障识别分类效果基本描述程序设计参考资料 分类效果 …
分类预测 | MATLAB实现GWO-BiGRU-Attention多输入分类预测
分类预测 | MATLAB实现GWO-BiGRU-Attention多输入分类预测 目录 分类预测 | MATLAB实现GWO-BiGRU-Attention多输入分类预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.GWO-BiGRU-Attention 数据分类预测程序 2.代码说明:基于灰狼优化算法(GW…
分类预测 | Matlab基于TTAO-CNN-LSTM-Attention三角拓扑聚合优化算法优化卷积神经网络-长短期记忆网络-注意力机制的数据分类预测
分类预测 | Matlab基于TTAO-CNN-LSTM-Attention三角拓扑聚合优化算法优化卷积神经网络-长短期记忆网络-注意力机制的数据分类预测 目录 分类预测 | Matlab基于TTAO-CNN-LSTM-Attention三角拓扑聚合优化算法优化卷积神经网络-长短期记忆网络-注意力机制的数据分类预测分类效果基…

多维时序 | MATLAB实现SCNGO-BiLSTM-Attention多变量时间序列预测
多维时序 | MATLAB实现SCNGO-BiLSTM-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现SCNGO-BiLSTM-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现SCNGO-BiLSTM-Attention多变量时间序列预测。 模型描…

多维时序 | MATLAB实现BWO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现BWO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现BWO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现BWO-CNN-B…

多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现KOA-CNN-B…
多维时序 | MATLAB实现SSA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现SSA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现SSA-CNN-LST…
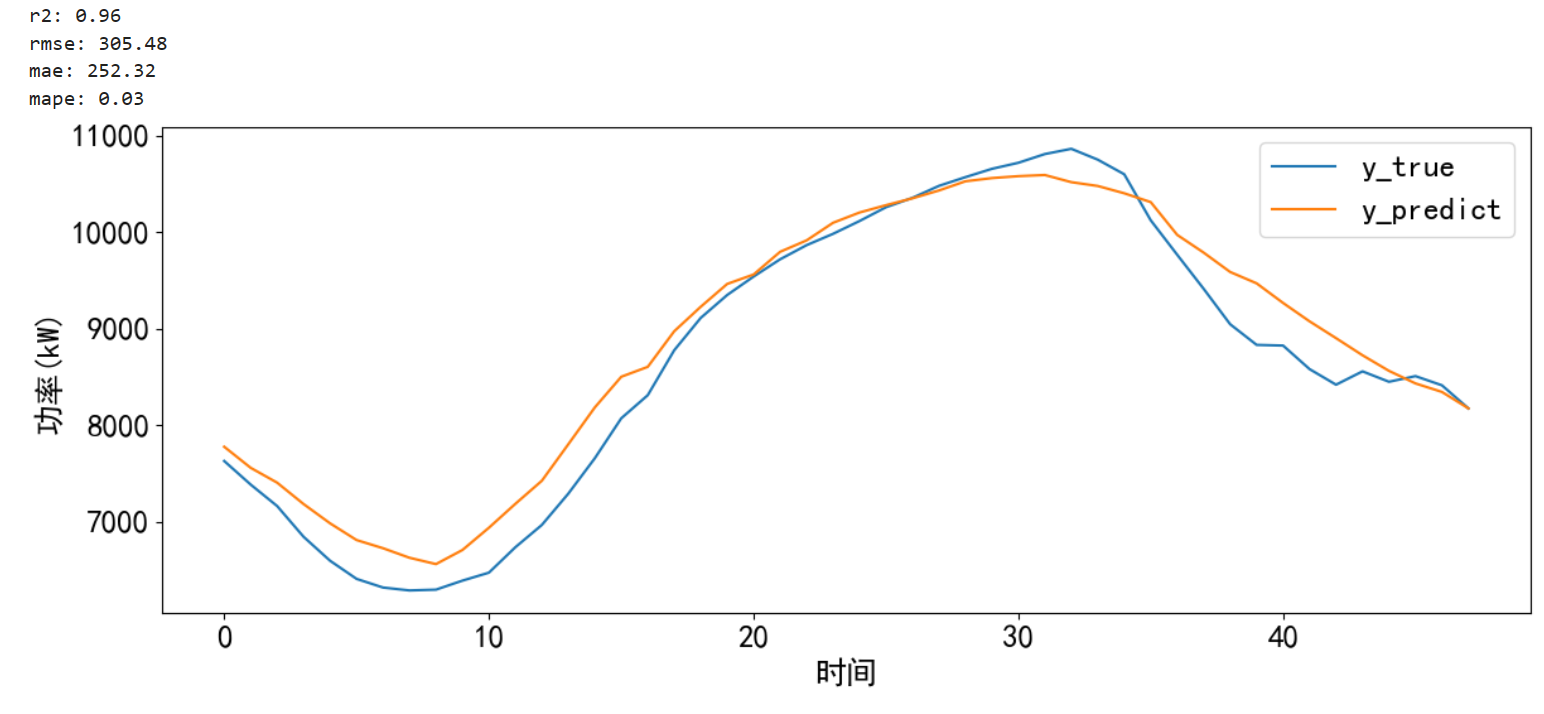
时间序列预测 — CNN-LSTM-Attention实现多变量负荷预测(Tensorflow):多变量滚动
专栏链接:https://blog.csdn.net/qq_41921826/category_12495091.html 专栏内容 所有文章提供源代码、数据集、效果可视化 文章多次上领域内容榜、每日必看榜单、全站综合热榜 时间序列预测存在的问题 现有的大量方法没有真正的预测未…
多维时序 | MATLAB实现BiTCN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现SABO-CNN-GRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现SABO-CNN-GRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现BiTCN-BiGRU-Attention多变量时间序列预测。 模型描…

看了这篇你还不懂BERT,那你就过来打死我吧
目录
1. Word Embedding. 1
1.1 基于共现矩阵的词向量... 1
1.2 基于语言模型的词向量... 2
2. RNN/LSTM/GRU.. 5
2.1 RNN.. 5
2.2 LSTM 通过门的机制来避免梯度消失... 6
2.3 GRU 把遗忘门和输入门合并成一个更新门... 6
3. seq2seq模型... 8
3.1 朴素的seq2seq模型.…

多维时序 | Matlab实现CNN-BiGRU-Mutilhead-Attention卷积双向门控循环单元融合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现CNN-BiGRU-Mutilhead-Attention卷积双向门控循环单元融合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现CNN-BiGRU-Mutilhead-Attention卷积双向门控循环单元融合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料 效果一…
分类预测 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积神经网络-长短期记忆网络融合多头注意力机制多特征分类预测
分类预测 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积神经网络-长短期记忆网络融合多头注意力机制多特征分类预测 目录 分类预测 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积神经网络-长短期记忆网络融合多头注意力机制多特征分类预测分类效果基本介绍模型描述程序设计参…
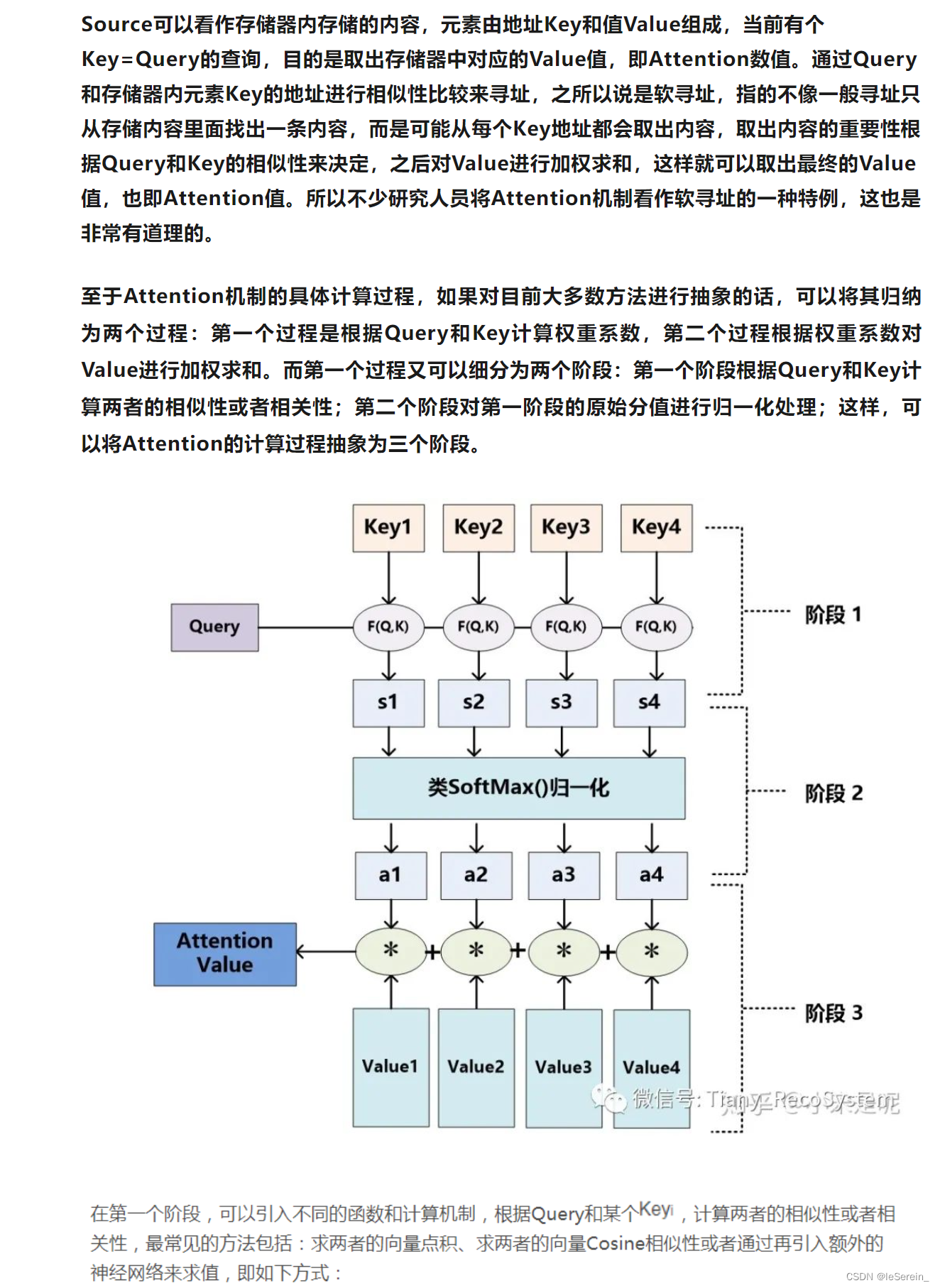
【Pytorch】CNN中的Attention
目录 更大层面上的Attention在attention中,怎么分区channel-wise还是spatial-wise举一个Spatial-Channel Attention的例子 使用广泛的Dot-product Attentionattention机制中的query,key,value的概念解释Attention的一个例子 更大层面上的Attention
在attention中&a…
学习transformer模型-矩阵乘法;与点积dot product的关系;计算attention
矩阵乘法: 1、当矩阵A的列数(column)等于矩阵B的行数(row)时,A与B可以相乘。 Ankie的评论:一个人是站着的,一个人是躺着的,站着的高度躺着的长度。 在计算attention的时候…

多维时序 | Matlab实现BiGRU-Mutilhead-Attention双向门控循环单元融合多头注意力机制多变量时序预测
多维时序 | Matlab实现BiGRU-Mutilhead-Attention双向门控循环单元融合多头注意力机制多变量时序预测 目录 多维时序 | Matlab实现BiGRU-Mutilhead-Attention双向门控循环单元融合多头注意力机制多变量时序预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.多维时序 …
分类预测 | Matlab实现基于TSOA-CNN-GRU-Attention的数据分类预测
分类预测 | Matlab实现基于TSOA-CNN-GRU-Attention的数据分类预测 目录 分类预测 | Matlab实现基于TSOA-CNN-GRU-Attention的数据分类预测效果一览基本介绍研究内容程序设计参考资料 效果一览 基本介绍 Matlab实现分类预测 | Matlab实现基于TSOA-CNN-GRU-Attention的数据分类预…
分类预测 | MATLAB实现CNN-BiGRU-Attention多输入分类预测
分类预测 | MATLAB实现CNN-BiGRU-Attention多输入单输出分类预测 目录 分类预测 | MATLAB实现CNN-BiGRU-Attention多输入单输出分类预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 Matlab实现CNN-BiGRU-Attention多特征分类预测,卷积双向门控循环…
多维时序 | MATLAB实现WOA-CNN-LSTM-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现WOA-CNN-LSTM-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现WOA-CNN-LSTM-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描…

EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab)
EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab) 目录 EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经…
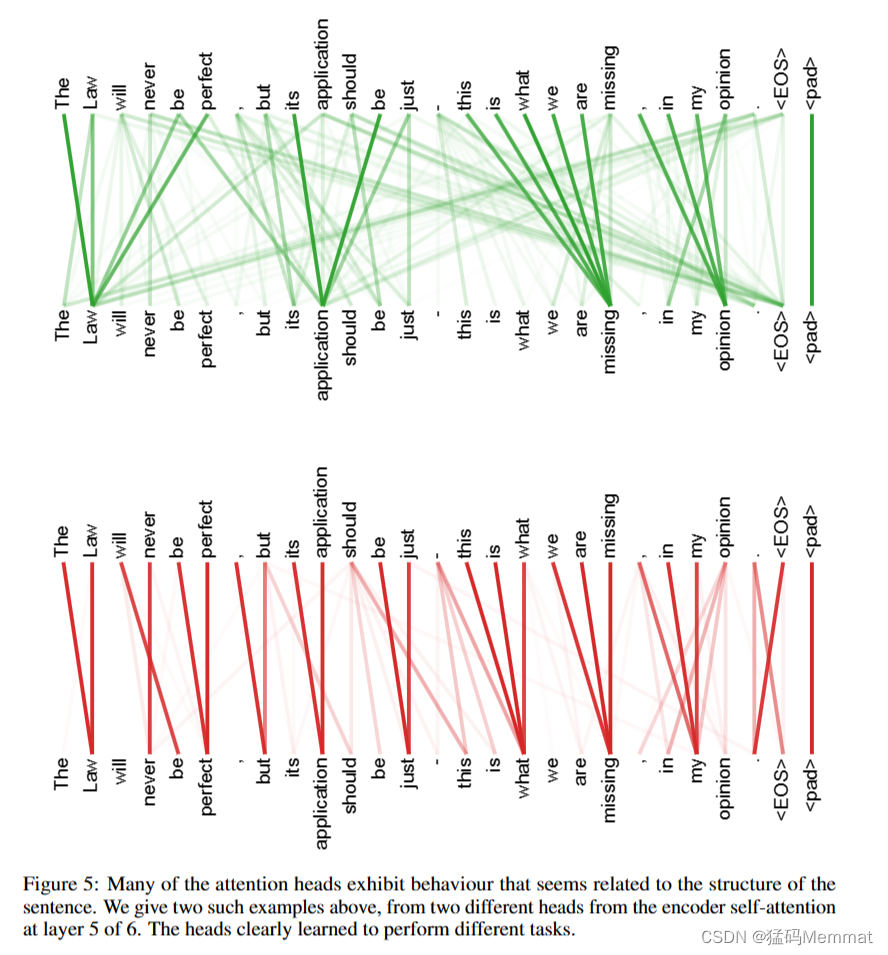
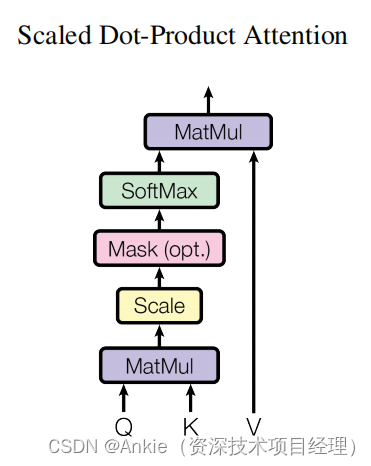
9k字长文理解Transformer: Attention Is All You Need
作者:猛码Memmat 目录 Abstract1 Introduction2 Background3 Model Architecture3.1 Encoder and Decoder Stacks3.2 Attention3.2.1 Scaled Dot-Product Attention3.2.2 Multi-Head Attention3.2.3 Applications of Attention in our Model 3.3 Position-wise Feed…

【LLM加速】注意力优化(基于位置/内容的稀疏注意力 | flashattention)
note
(1)近似注意力:
Routing Transformer采用K-means 聚类方法,针对Query和Key进行聚类,类中心向量集合为 { μ i } i 1 k \left\{\boldsymbol{\mu}_i\right\}_{i1}^k {μi}i1k ,其中k 是类中心的…

多维时序 | Matlab实现LSTM-Mutilhead-Attention长短期记忆神经网络融合多头注意力机制多变量时间序列预测模型
多维时序 | Matlab实现LSTM-Mutilhead-Attention长短期记忆神经网络融合多头注意力机制多变量时间序列预测模型 目录 多维时序 | Matlab实现LSTM-Mutilhead-Attention长短期记忆神经网络融合多头注意力机制多变量时间序列预测模型预测效果基本介绍程序设计参考资料 预测效果 基…

回归预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测
回归预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测 目录 回归预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测预测效果基本描述程序设计参考资料 预测效果…

多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.Matlab基于ZOA-CNN-BiGRU-Attention斑马优化卷积双向门控循环单元网络…
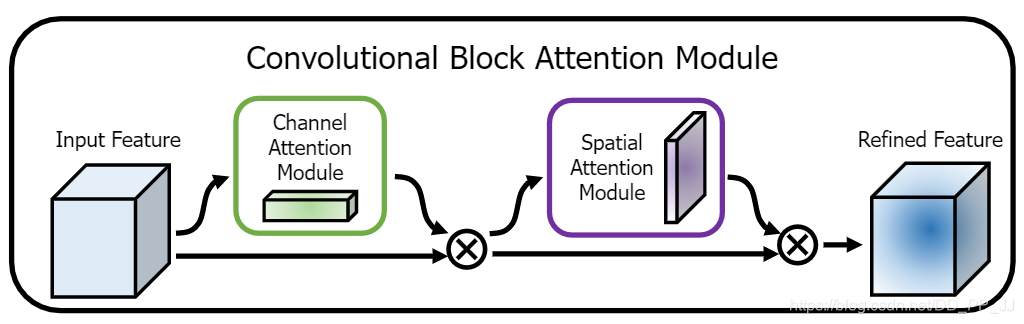
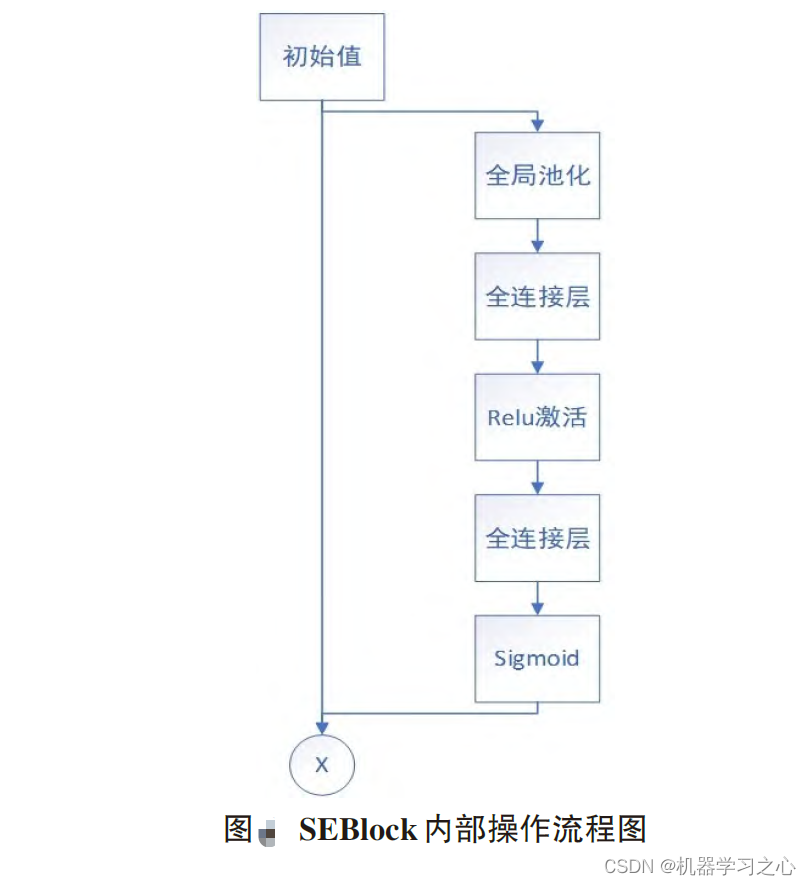
Attention机制中CBAM以及Dual pooling的pytorch实现
前言:虽然会pytorch框架中的一些基础操作,但是有很多实现直接让自己写还是挺困难的。本次的代码参考senet中的channel-wise加权,CBAM中的channel-attention和spatial-attention, 另外还有kaggle Mastergray 分享的Dual pooling。由于没有特别…

EI级 | Matlab实现TCN-GRU-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-GRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 EI级 | Matlab实现TCN-GRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.【EI级】Matlab实现TCN-GRU-Multihead-Attention…

EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.【EI级】 Matlab实现TCN-BiGRU-Mult…

多维时序 | Matlab实现GWO-TCN-Multihead-Attention灰狼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现GWO-TCN-Multihead-Attention灰狼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现GWO-TCN-Multihead-Attention灰狼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料 效…

多维时序 | MATLAB实现SAO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现SAO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现SAO-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现SAO-CNN-B…
多维时序 | Matlab实现WOA-TCN-Multihead-Attention鲸鱼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现WOA-TCN-Multihead-Attention鲸鱼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现WOA-TCN-Multihead-Attention鲸鱼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料 效…
分类预测 | MATLAB实现SCNGO-CNN-LSTM-Attention数据分类预测
分类预测 | MATLAB实现SCNGO-CNN-LSTM-Attention数据分类预测 目录 分类预测 | MATLAB实现SCNGO-CNN-LSTM-Attention数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.SCNGO-CNN-LSTM-Attention数据分类预测程序,改进算法,融合正余弦和…
多维时序 | Matlab实现GRO-CNN-BiLSTM-Attention淘金算法优化卷积神经网络-双向长短期记忆网络结合注意力机制多变量时间序列预测
多维时序 | Matlab实现GRO-CNN-BiLSTM-Attention淘金算法优化卷积神经网络-双向长短期记忆网络结合注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现GRO-CNN-BiLSTM-Attention淘金算法优化卷积神经网络-双向长短期记忆网络结合注意力机制多变量时间序列预测效果一览基…
多维时序 | MATLAB实现WOA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现WOA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现WOA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现WOA-CNN-LST…
多维时序 | MATLAB实现KOA-CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现KOA-CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现KOA-CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现KOA-CNN-BiGRU-Attention多变量时间序列预测,KOA-…
多维时序 | MATLAB实现RIME-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现RIME-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现RIME-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现RIME-CNN-…

EI级 | Matlab实现TCN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 EI级 | Matlab实现TCN-BiLSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.【EI级】Matlab实现TCN-BiLSTM-Multihead-…

时序预测 | Python基于Multihead-Attention-TCN-LSTM的时间序列预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 时序预测 | Python基于Multihead-Attention-TCN-LSTM的时间序列预测 Multihead-Attention-TCN-LSTM(多头注意力-TCN-LSTM)是一种结合了多个注意力机制、时序卷积网络(TCN࿰…
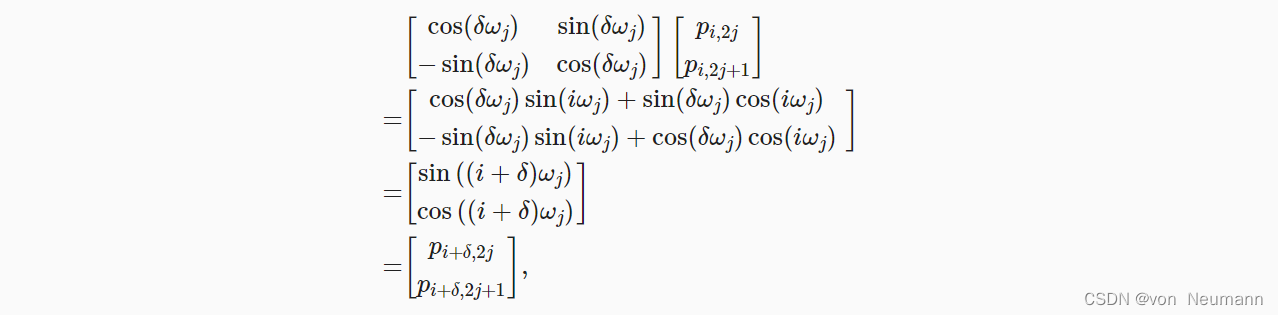
深入理解深度学习——注意力机制(Attention Mechanism):位置编码(Positional Encoding)
分类目录:《深入理解深度学习》总目录
相关文章: 注意力机制(AttentionMechanism):基础知识 注意力机制(AttentionMechanism):注意力汇聚与Nadaraya-Watson核回归 注意力机制&#…
分类预测 | MATLAB实现SSA-CNN-BiLSTM-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现SSA-CNN-BiLSTM-Attention数据分类预测(SE注意力机制) 目录 分类预测 | MATLAB实现SSA-CNN-BiLSTM-Attention数据分类预测(SE注意力机制)分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MAT…

计算机视觉中的注意力机制
本文将会介绍计算机视觉中的注意力(visual attention)机制,本文为了扩大受众群体以及增加文章的可读性,采用递进式的写作方式。第1部分的全部以及第2部分的大部分是没有专业障碍的,后续的部分是为了更深入地了解计算机…

多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测 1.程…
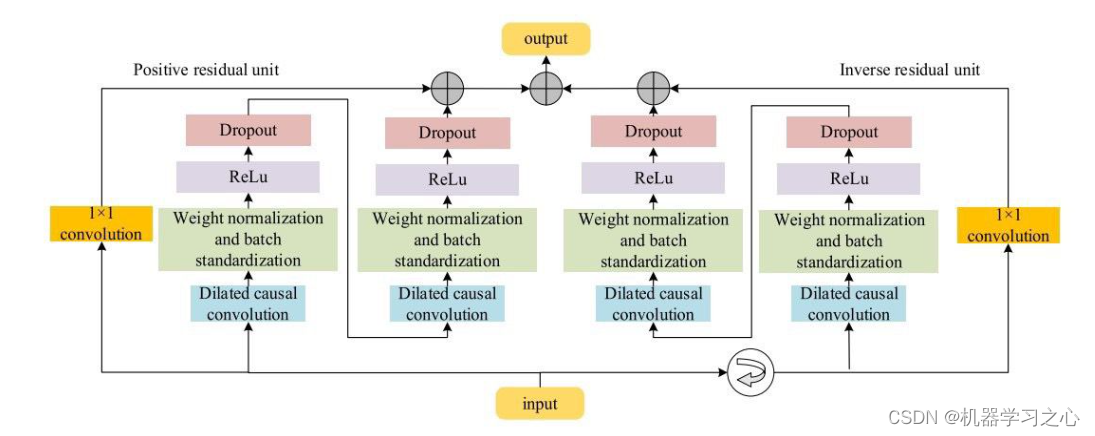
多维时序 | MATLAB实现BiTCN-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现BiTCN-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现BiTCN-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现BiTCN-Multihea…
多维时序 | MATLAB实现CNN-BiLSTM-Attention多变量时间序列预测
多维时序 | MATLAB实现CNN-BiLSTM-Attention多变量时间序列预测 目录多维时序 | MATLAB实现CNN-BiLSTM-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料预测效果 基本介绍 MATLAB实现CNN-BiLSTM-Attention多变量时间序列预测,CNN-BiLSTM-Atte…

负荷预测 | Matlab基于TCN-GRU-Attention单输入单输出时间序列多步预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于TCN-GRU-Attention单输入单输出时间序列多步预测; 2.单变量时间序列数据集,采用前12个时刻预测未来96个时刻的数据; 3.excel数据方便替换,运行环境matlab20…
回归预测 | Matlab实现CPO-CNN-LSTM-Attention冠豪猪优化卷积长短期记忆神经网络注意力机制多变量回归预测(SE注意力机制)
回归预测 | Matlab实现CPO-CNN-LSTM-Attention冠豪猪优化卷积长短期记忆神经网络注意力机制多变量回归预测(SE注意力机制) 目录 回归预测 | Matlab实现CPO-CNN-LSTM-Attention冠豪猪优化卷积长短期记忆神经网络注意力机制多变量回归预测(SE注…

Self-Attention-Generative-Adversarial-Networks(2019 ICML,HanZhang IanGoodfellow)
文章目录1 背景2 挑战3 创新4 方法5 实验1 背景
自从GAN提出后,其在图像合成领域一直非常火热,尤其是基于深度卷积神经网络的GAN。
对于多分类实验结果不理想,GAN擅于获取具有连续几何结构的模式,比如能精确模拟狗的毛发而对几只…

高创新 | Matlab实现OOA-CNN-GRU-Attention鱼鹰算法优化卷积门控循环单元注意力机制多变量回归预测
高创新 | Matlab实现OOA-CNN-GRU-Attention鱼鹰算法优化卷积门控循环单元注意力机制多变量回归预测 目录 高创新 | Matlab实现OOA-CNN-GRU-Attention鱼鹰算法优化卷积门控循环单元注意力机制多变量回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现OOA…

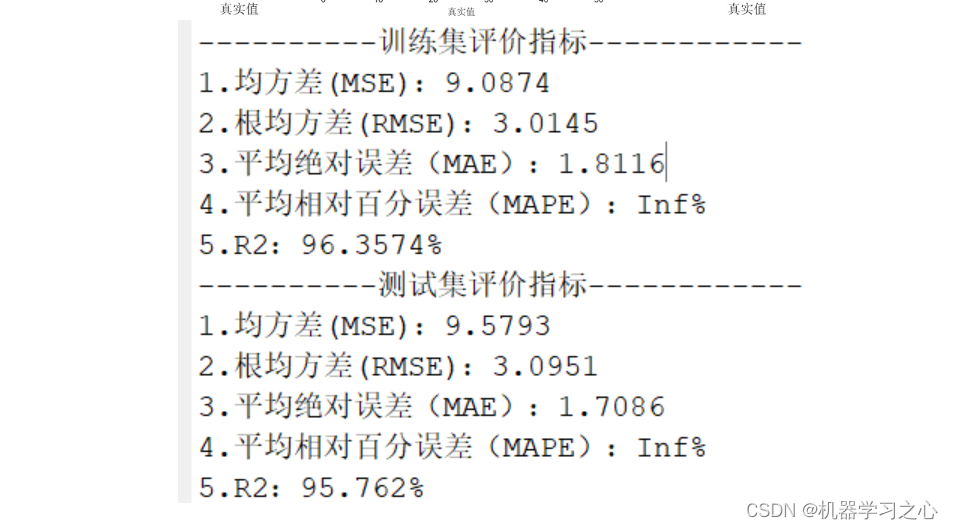
基于PSO优化的CNN-LSTM-Attention的时间序列回归预测matlab仿真
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1卷积神经网络(CNN)在时间序列中的应用
4.2 长短时记忆网络(LSTM)处理序列依赖关系
4.3 注意力机制(Attention)
5…

NLP学习笔记(五) 注意力机制
大家好,我是半虹,这篇文章来讲注意力机制 (Attention Mechanism) 在序列到序列模型中的应用 在上一篇文章中,我们介绍了序列到序列模型,其工作流程可以概括为以下两个步骤
首先,用编码器将输入序列编码成上下文向量&a…

基于CNN-GRU-Attention的时间序列回归预测matlab仿真
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1 CNN(卷积神经网络)部分
4.2 GRU(门控循环单元)部分
4.3 Attention机制部分
5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版…
NLP中的Seq2Seq与attention注意力机制
文章目录 RNN循环神经网络seq2seq模型Attention(注意力机制)总结参考文献RNN循环神经网络
RNN循环神经网络被广泛应用于自然语言处理中,对于处理序列数据有很好的效果,常见的序列数据有文本、语音等,至于为什么要用到循环神经网络而不是传统的神经网络,我们在这里举一个…
多维时序 | Matlab实现RIME-TCN-Multihead-Attention霜冰算法优化时间卷积网络结合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现RIME-TCN-Multihead-Attention霜冰算法优化时间卷积网络结合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现RIME-TCN-Multihead-Attention霜冰算法优化时间卷积网络结合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料…
时序预测 | MATLAB实现WOA-CNN-LSTM-Attention时间序列预测(SE注意力机制)
时序预测 | MATLAB实现WOA-CNN-LSTM-Attention时间序列预测(SE注意力机制) 目录 时序预测 | MATLAB实现WOA-CNN-LSTM-Attention时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描述 1.MATLAB实…
分类预测 | MATLAB实现SSA-CNN-GRU-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现SSA-CNN-GRU-Attention数据分类预测(SE注意力机制) 目录 分类预测 | MATLAB实现SSA-CNN-GRU-Attention数据分类预测(SE注意力机制)分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现…
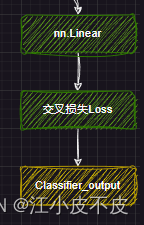
Llama 架构分析
从代码角度进行Llama 架构分析 Llama 架构分析前言Llama 架构分析分词网络主干DecoderLayerAttentionMLP 下游任务因果推理文本分类 Llama 架构分析
前言 Meta 开发并公开发布了 Llama系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参…

分类预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多特征分类预测
分类预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多特征分类预测 目录 分类预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多特征分类预测分类效果基本描述程序设计参考资料 分类效果…
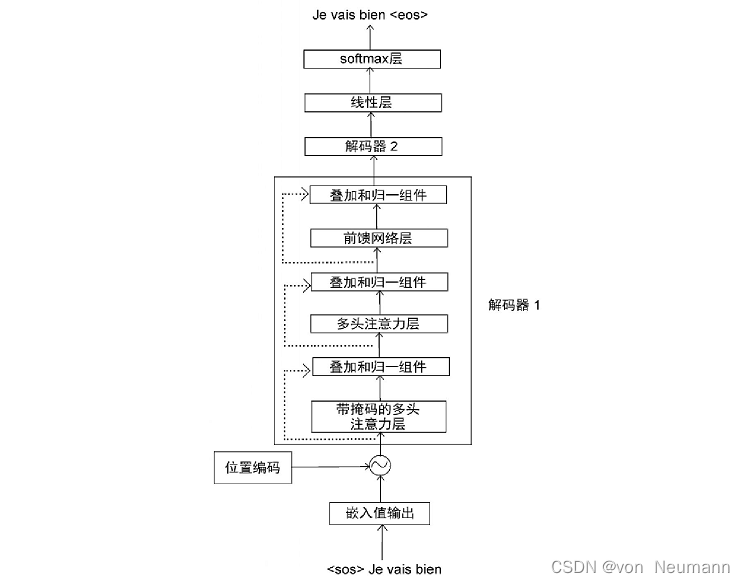
深入理解深度学习——Transformer:解码器(Decoder)部分
分类目录:《深入理解深度学习》总目录
相关文章: 注意力机制(Attention Mechanism):基础知识 注意力机制(Attention Mechanism):注意力汇聚与Nadaraya-Watson核回归 注意力机制&…
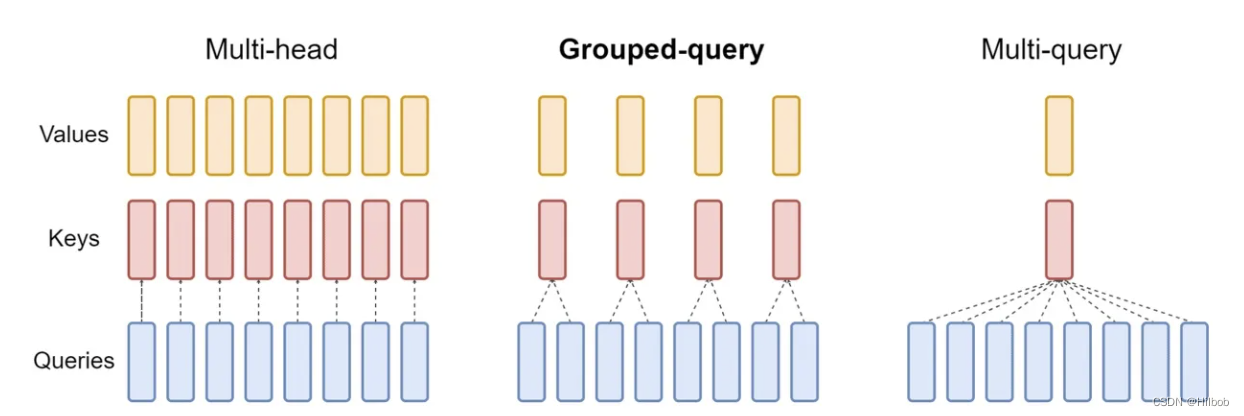
【NLP】MHA、MQA、GQA机制的区别
Note
LLama2的注意力机制使用了GQA。三种机制的图如下:
MHA机制(Multi-head Attention)
MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 V…
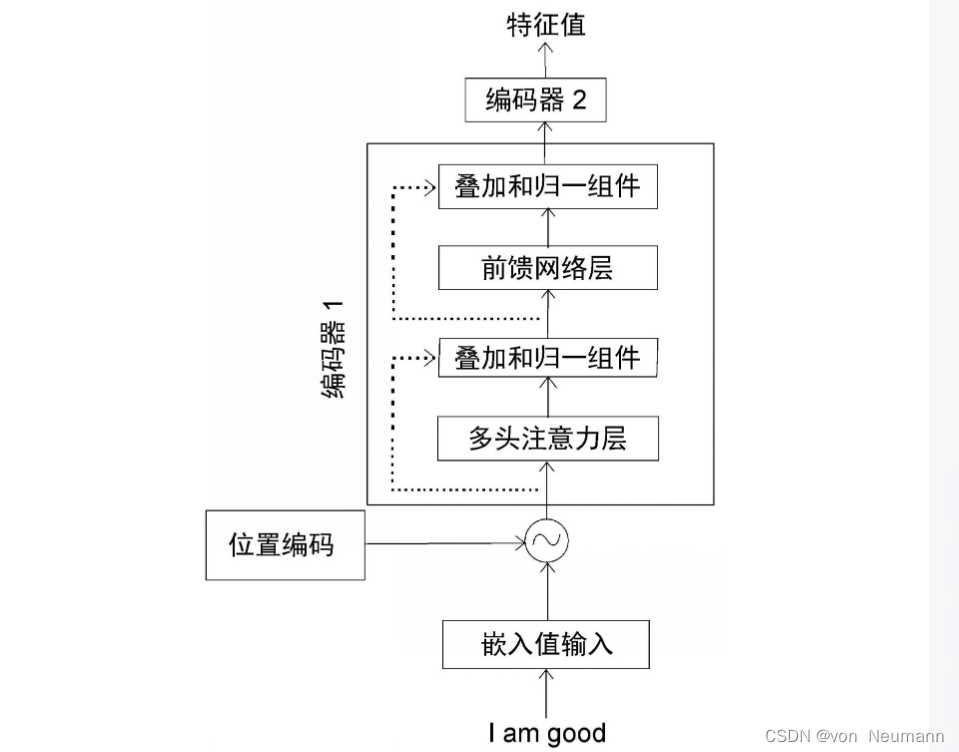
深入理解深度学习——Transformer:编码器(Encoder)部分
分类目录:《深入理解深度学习》总目录 Transformer中的编码器不止一个,而是由一组 N N N个编码器串联而成。一个编码器的输出作为下一个编码器的输入。在下图中有 N N N个编码器,每一个编码器都从下方接收数据,再输出给上方。以此…
时序预测 | MATLAB实现WOA-CNN-GRU-Attention时间序列预测(SE注意力机制)
时序预测 | MATLAB实现WOA-CNN-GRU-Attention时间序列预测(SE注意力机制) 目录 时序预测 | MATLAB实现WOA-CNN-GRU-Attention时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描述 1.MATLAB实现…
「解析」Attention机制
Attention函数的本质可以被描述为一个 Query 到 Key-Value对 的映射,这个映射的目的:为了给重要的部分分配更多的概率权重。
计算过程主要分为以下三步:
通过点乘、加法等其他办法计算 Q:query 和 每个K:key 之间的相似度 s i m ( Q , K i…
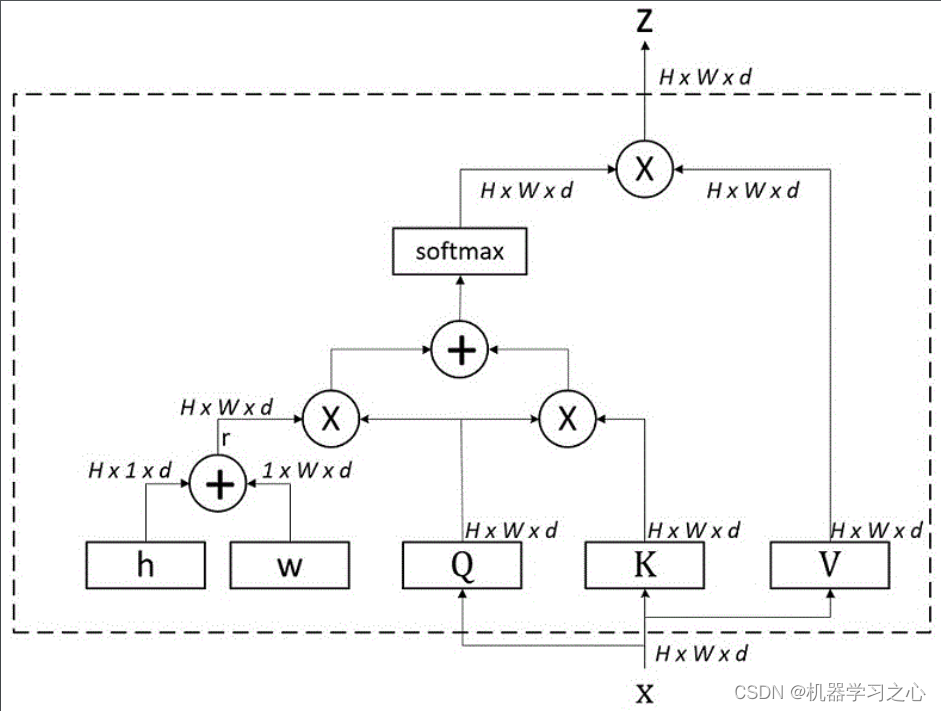
多维时序 | MATLAB实CNN-Mutilhead-Attention卷积神经网络融合多头注意力机制多变量时间序列预测
多维时序 | MATLAB实CNN-Mutilhead-Attention卷积神经网络融合多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实CNN-Mutilhead-Attention卷积神经网络融合多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | …
多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现WOA-CNN-GRU-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描述…

多维时序 | Matlab实现CNN-GRU-Mutilhead-Attention卷积门控循环单元融合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现CNN-GRU-Mutilhead-Attention卷积门控循环单元融合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现CNN-GRU-Mutilhead-Attention卷积门控循环单元融合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍…
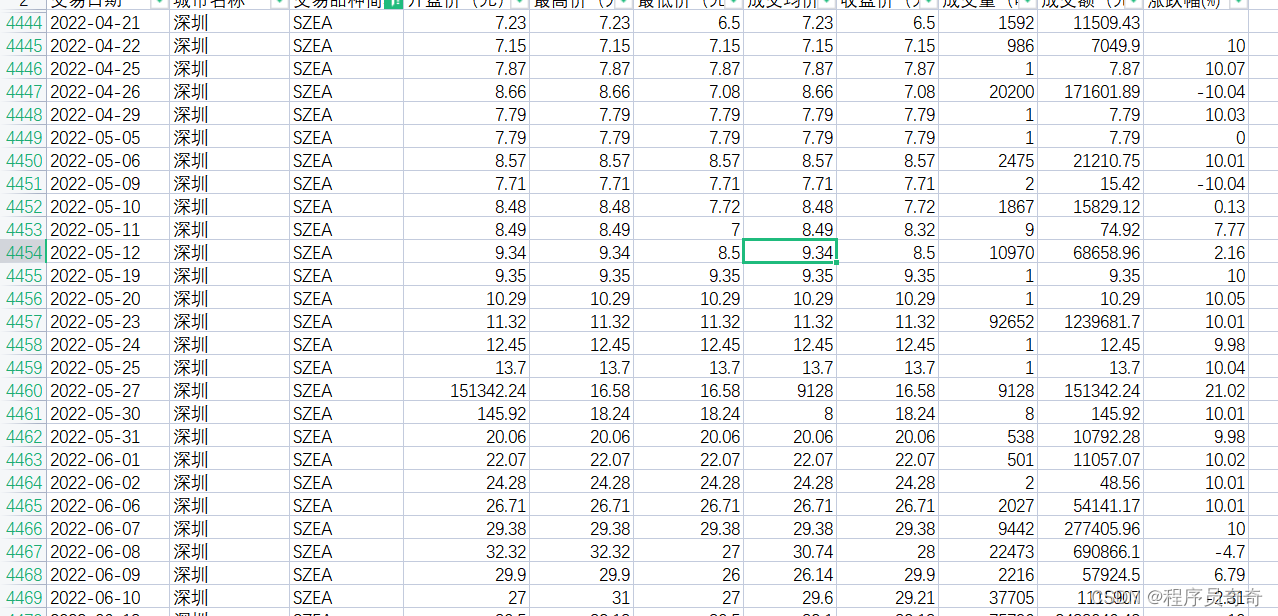
VMD-Attention-LSTM 价格预测实战
VMD-Attention-LSTM时间序列价格预测实战 完整数据代码可直接运行_哔哩哔哩_bilibili 数据展示:数据有几万条 足够的 主要模型代码:
import tensorflow as tfdef attention_3d_block(inputs,TIME_STEPS,SINGLE_ATTENTION_VECTOR):# inputs.shape = (batch_size, time_steps,…
多维时序 | MATLAB实现SSA-CNN-LSTM-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现SSA-CNN-LSTM-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现SSA-CNN-LSTM-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描…
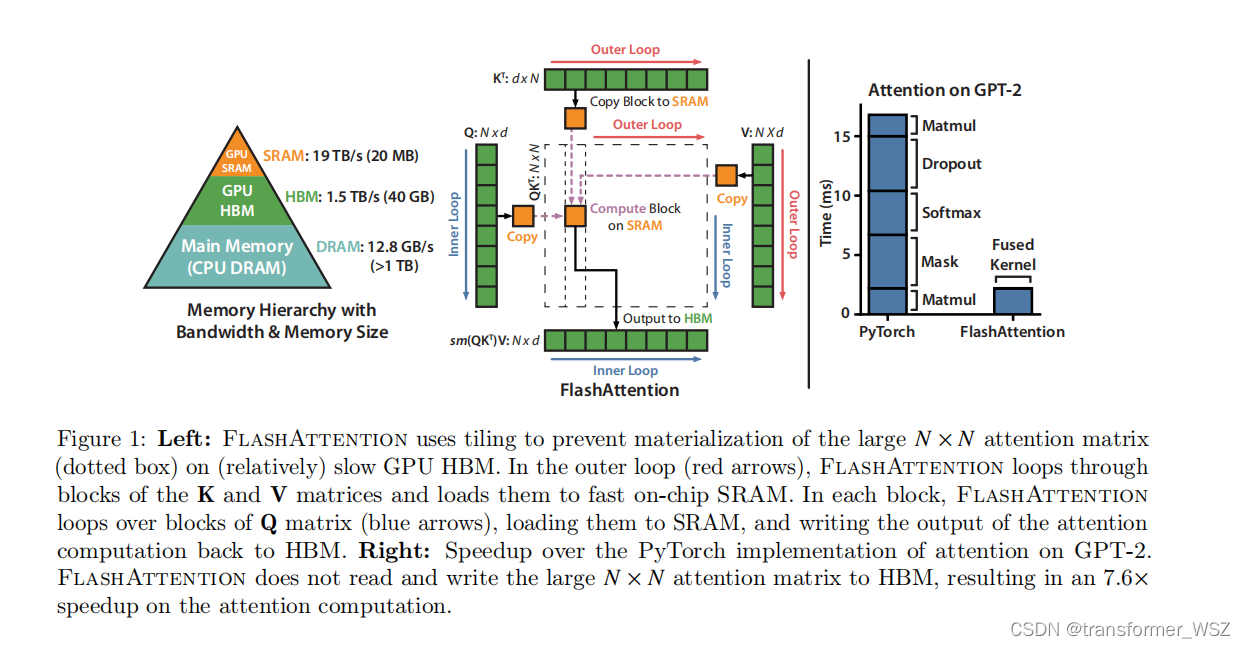
Flash-Attention
这是一篇硬核的优化Transformer的工作。众所周知,Transformer模型的计算量和储存复杂度是 O ( N 2 ) O(N^2) O(N2) 。尽管先前有了大量的优化工作,比如LongFormer、Sparse Transformer、Reformer等等,一定程度上减轻了Transformer的资源消耗…
多维时序 | MATLAB实现SSA-CNN-BiGRU-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现SSA-CNN-BiGRU-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现SSA-CNN-BiGRU-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本…
【深度学习】图像自然语言描述生成
案例 6:图像自然语言描述生成(让计算机“看图说话”)
相关知识点:RNN、Attention 机制、图像和文本数据的处理
1 任务目标
1.1 任务和数据简介
本次案例将使用深度学习技术来完成图像自然语言描述生成任务,输入…

TinyBERT论文及代码详细解读
简介
TinyBERT是知识蒸馏的一种模型,于2020年由华为和华中科技大学来拟合提出。
常见的模型压缩技术主要分为:
量化权重减枝知识蒸馏
为了加快推理速度并减小模型大小,同时又保持精度,Tinybert首先提出了一种新颖的transforme…
36k字从Attention解读Transformer及其在Vision中的应用(pytorch版)
文章目录 0.卷积操作1.注意力1.1 注意力概述(Attention)1.1.1 Encoder-Decoder1.1.2 查询、键和值1.1.3 注意力汇聚: Nadaraya-Watson 核回归1.2 注意力评分函数1.2.1 加性注意力1.2.2 缩放点积注意力1.3 自注意力(Self-Attention)1.3.1 自注意力的定义和计算1.3.2 自注意…
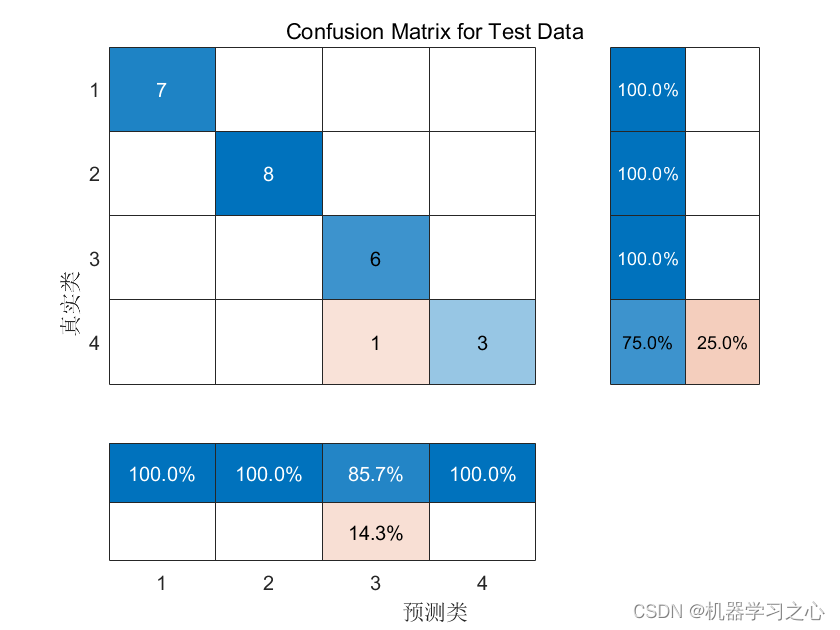
分类预测 | MATLAB实现GWO-BiLSTM-Attention多输入分类预测
分类预测 | MATLAB实现GWO-BiLSTM-Attention多输入分类预测 目录 分类预测 | MATLAB实现GWO-BiLSTM-Attention多输入分类预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.GWO-BiLSTM-Attention 数据分类预测程序 2.代码说明:基于灰狼优化算法(…
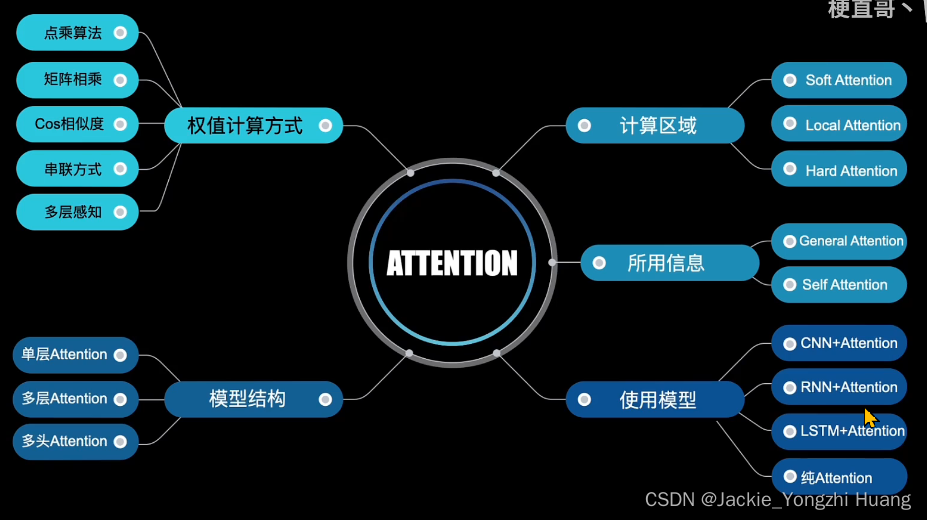
关于深度学习中Attention的一些简单理解
Attention 机制
Attention应用在了很多最流行的模型中,Transformer、BERT、GPT等等。
Attention就是计算一个加权平均;通过加权平均的权值来自计算每个隐藏层之间的相关度;
示例
Attention 机制
Attention应用在了很多最流行的模型中&am…
时序预测 | MATLAB实现CNN-BiGRU-Attention时间序列预测
时序预测 | MATLAB实现CNN-BiGRU-Attention时间序列预测 目录 时序预测 | MATLAB实现CNN-BiGRU-Attention时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现CNN-BiGRU-Attention时间序列预测,CNN-BiGRU-Attention结合注意力机制时…
回归预测 | Matlab实现SSA-BiLSTM-Attention麻雀算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测
回归预测 | Matlab实现SSA-BiLSTM-Attention麻雀算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测 目录 回归预测 | Matlab实现SSA-BiLSTM-Attention麻雀算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测预测效果基本描述程序设计参考资料 预测效果 基…
分类预测 | Matlab实现LSTM-Attention-Adaboost基于长短期记忆网络融合注意力机制的Adaboost数据分类预测/故障识别
分类预测 | Matlab实现LSTM-Attention-Adaboost基于长短期记忆网络融合注意力机制的Adaboost数据分类预测/故障识别 目录 分类预测 | Matlab实现LSTM-Attention-Adaboost基于长短期记忆网络融合注意力机制的Adaboost数据分类预测/故障识别分类效果基本描述程序设计参考资料 分类…

引入Attention的Seq2Seq模型-机器翻译
在上一篇博客中,我们介绍了 基于Seq2Seq模型的机器翻译。今天,在此基础上,对模型加入注意力机制Attention。
模型结构
首先,我们先了解一下模型的结构,基本与Seq2Seq模型大体一致:
首先,第一…
C刊级 | Matlab实现GWO-BiTCN-BiGRU-Attention灰狼算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测
C刊级 | Matlab实现GWO-BiTCN-BiGRU-Attention灰狼算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测 目录 C刊级 | Matlab实现GWO-BiTCN-BiGRU-Attention灰狼算法优化双向时间卷积双向门控循环单元融合注意力机制多变量回归预测效果一览基本介绍程序设计参考…
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-CNN-BiGRU-Attention多特征分类预测,多特征输入模型&…
Transformer模型-用jupyter演示逐步计算attention
学习transformer模型-用jupyter演示如何计算attention,不含multi-head attention,但包括权重矩阵W。
input embedding:文本嵌入
每个字符用长度为5的向量表示: 注意力公式: 1,准备Q K V: 先 生…

分类预测 | MATLAB实现SMA-CNN-BiLSTM-Attention多输入分类预测
分类预测 | MATLAB实现SMA-CNN-BiLSTM-Attention多输入分类预测 目录 分类预测 | MATLAB实现SMA-CNN-BiLSTM-Attention多输入分类预测分类效果基本介绍模型描述程序设计参考资料 分类效果 基本介绍 1.MATLAB实现SMA-CNN-BiLSTM-Attention多输入分类预测,CNN-BiLSTM结…

EI级 | Matlab实现TCN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测 目录 EI级 | Matlab实现TCN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.【EI级】Matlab实现TCN-LSTM-Multihead-Attent…
多维时序 | MATLAB实现TSOA-TCN-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现TSOA-TCN-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现TSOA-TCN-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现TSOA-TCN-Multihead-…

GPT 的基础 - T(Transformer)
我们知道GPT的含义是: Generative - 生成下一个词 Pre-trained - 文本预训练 Transformer - 基于Transformer架构
我们看到Transformer模型是GPT的基础,这篇博客梳理了一下Transformer的知识点。 BERT: 用于语言理解。(Transformer的Encoder…
分类预测 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆网络多头注意力机制多特征分类预测
分类预测 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆网络多头注意力机制多特征分类预测 目录 分类预测 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆网络多头注意力机制多特征分类预测分类效果基本介绍模型描述程序设计参考资料 分类效果…

注意力机制 Attention模型 global attention 和 local attention
Attention model 可以应用在图像领域也可以应用在自然语言识别领域
本文讨论的Attention模型是应用在自然语言领域的Attention模型,本文以神经网络机器翻译为研究点讨论注意力机制,参考文献《Effective Approaches to Attention-based Neural Machine T…
多维时序 | MATLAB实现SSA-CNN-BiLSTM-Attention多变量时间序列预测(SE注意力机制)
多维时序 | MATLAB实现SSA-CNN-BiLSTM-Attention多变量时间序列预测(SE注意力机制) 目录 多维时序 | MATLAB实现SSA-CNN-BiLSTM-Attention多变量时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基…
分类预测 | MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制) 目录 分类预测 | MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MATLA…
分类预测 | MATLAB实现SSA-CNN-LSTM-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现SSA-CNN-LSTM-Attention数据分类预测(SE注意力机制) 目录 分类预测 | MATLAB实现SSA-CNN-LSTM-Attention数据分类预测(SE注意力机制)分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MATLAB实…

多维时序 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积长短期记忆神经网络融合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积长短期记忆神经网络融合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积长短期记忆神经网络融合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料 效果…

加速attention计算的工业标准:flash attention 1和2算法的原理及实现
transformers目前大火,但是对于长序列来说,计算很慢,而且很耗费显存。对于transformer中的self attention计算来说,在时间复杂度上,对于每个位置,模型需要计算它与所有其他位置的相关性,这样的计…

SCI一区 | Matlab实现GWO-TCN-BiGRU-Attention灰狼算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现GWO-TCN-BiGRU-Attention灰狼算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现GWO-TCN-BiGRU-Attention灰狼算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述程序…
回归预测 | MATLAB实现SSA-CNN-GRU-Attention多变量回归预测(SE注意力机制)
回归预测 | MATLAB实现SSA-CNN-GRU-Attention多变量回归预测(SE注意力机制) 目录 回归预测 | MATLAB实现SSA-CNN-GRU-Attention多变量回归预测(SE注意力机制)预测效果基本描述程序设计参考资料 预测效果 基本描述 1.Matlab实现SSA…
SCI一区 | Matlab实现PSO-TCN-BiGRU-Attention粒子群算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现PSO-TCN-BiGRU-Attention粒子群算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现PSO-TCN-BiGRU-Attention粒子群算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述…

SCI一区级 | Matlab实现RIME-CNN-BiLSTM-Mutilhead-Attention多变量多步时序预测
SCI一区级 | Matlab实现RIME-CNN-BiLSTM-Mutilhead-Attention多变量多步时序预测 目录 SCI一区级 | Matlab实现RIME-CNN-BiLSTM-Mutilhead-Attention多变量多步时序预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现RIME-CNN-BiLSTM-Mutilhead-Attention多…
学习人工智能-点积dot product,计算transformer模型里面的attention
因为transformer模型里面计算attention用到了点积dot product来计算相似度 or 距离,所以补充一下点积的知识。
点积的代数定义:
点积在数学中,又称数量积(dot product; scalar product),是指接受在实数R上…
SCI一区 | Matlab实现SSA-TCN-BiGRU-Attention麻雀算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现SSA-TCN-BiGRU-Attention麻雀算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现SSA-TCN-BiGRU-Attention麻雀算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述程序…
多维时序 | Matlab实现GRO-CNN-LSTM-Attention淘金算法优化卷积神经网络-长短期记忆网络结合注意力机制多变量时间序列预测
多维时序 | Matlab实现GRO-CNN-LSTM-Attention淘金算法优化卷积神经网络-长短期记忆网络结合注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现GRO-CNN-LSTM-Attention淘金算法优化卷积神经网络-长短期记忆网络结合注意力机制多变量时间序列预测效果一览基本介绍程序设…

文本分类 之 有Attention的词向量平均模型 Word Average Model with Attention
这是一个文本分类的系列专题,将采用不同的方法有简单到复杂实现文本分类。 使用Stanford sentiment treebank 电影评论数据集 (Socher et al. 2013). 数据集可以从这里下载 链接:数据集 提取码:yeqw
本文的方法是在WordAverageModel的基础上…
时序预测 | MATLAB实现WOA-CNN-BiGRU-Attention时间序列预测(SE注意力机制)
时序预测 | MATLAB实现WOA-CNN-BiGRU-Attention时间序列预测(SE注意力机制) 目录 时序预测 | MATLAB实现WOA-CNN-BiGRU-Attention时间序列预测(SE注意力机制)预测效果基本描述模型描述程序设计参考资料 预测效果 基本描述 1.MATLA…
分类预测 | MATLAB实现WOA-CNN-GRU-Attention数据分类预测
分类预测 | MATLAB实现WOA-CNN-GRU-Attention数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-GRU-Attention数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现WOA-CNN-GRU-Attention数据分类预测,运行环境Matlab2021b及以上&…
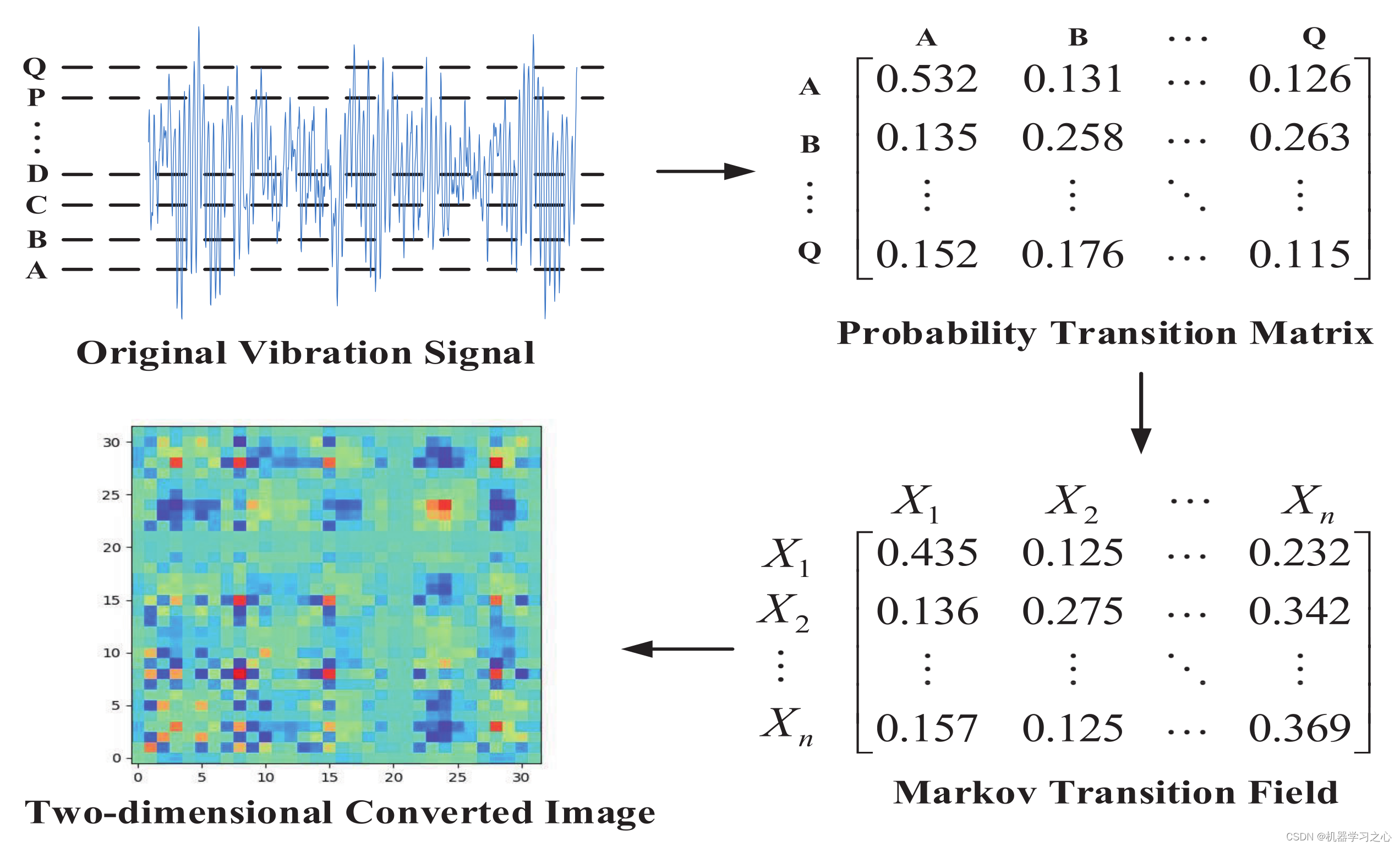
分类预测 | Matlab实现MTF-CNN-Mutilhead-Attention基于马尔可夫转移场-卷积神经网络融合多头注意力多特征数据分类预测
分类预测 | Matlab实现MTF-CNN-Mutilhead-Attention基于马尔可夫转移场-卷积神经网络融合多头注意力多特征数据分类预测 目录 分类预测 | Matlab实现MTF-CNN-Mutilhead-Attention基于马尔可夫转移场-卷积神经网络融合多头注意力多特征数据分类预测分类效果基本描述程序设计参考…
SCI一区 | Matlab实现RIME-TCN-BiGRU-Attention霜冰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现RIME-TCN-BiGRU-Attention霜冰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现RIME-TCN-BiGRU-Attention霜冰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述程…

多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计…
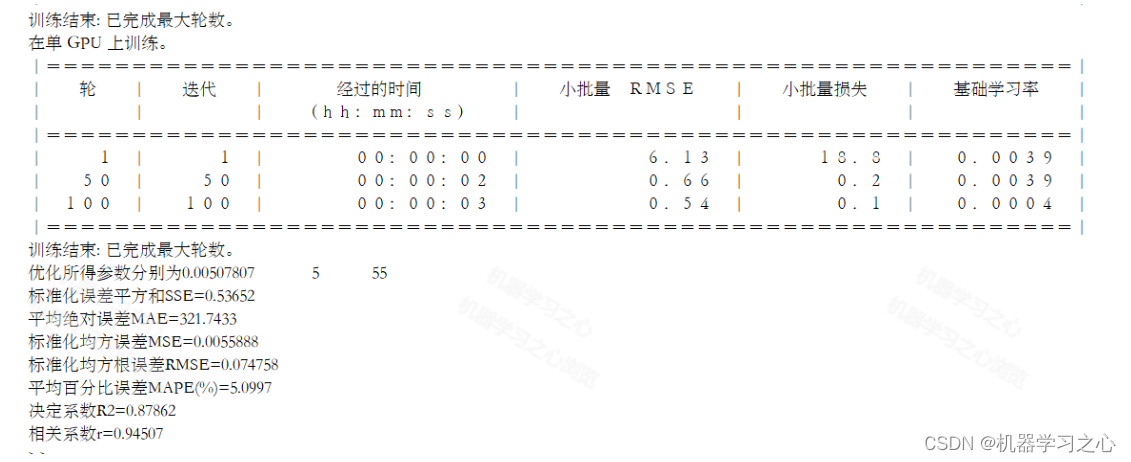
SCI一区级 | Matlab实现RIME-CNN-LSTM-Mutilhead-Attention多变量多步时序预测
SCI一区级 | Matlab实现RIME-CNN-LSTM-Mutilhead-Attention多变量多步时序预测 目录 SCI一区级 | Matlab实现RIME-CNN-LSTM-Mutilhead-Attention多变量多步时序预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现RIME-CNN-LSTM-Mutilhead-Attention霜冰算法…