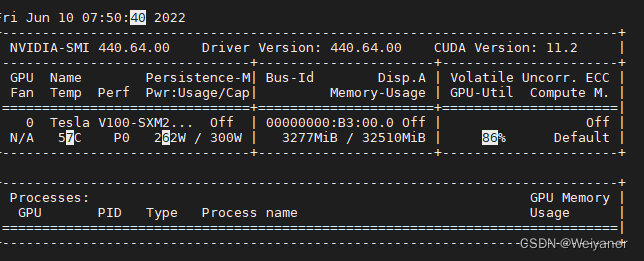
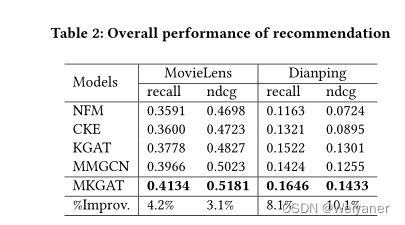
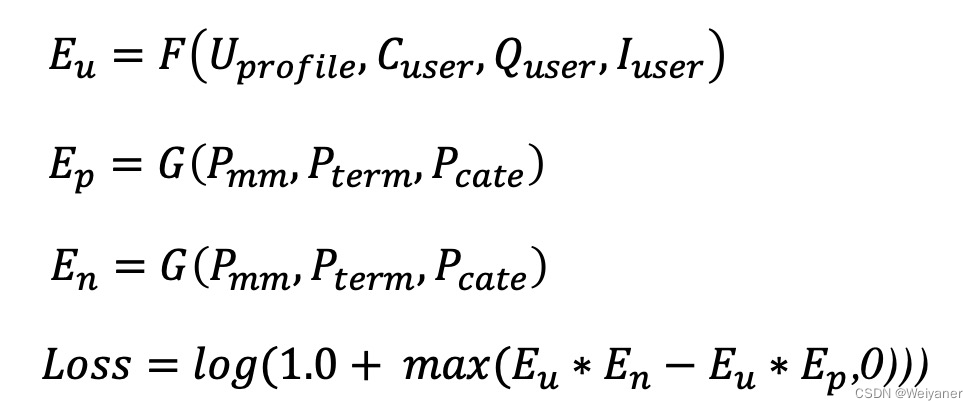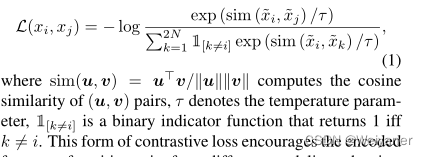本次课将演示一些shell工具以及bash脚本语言的基础用法。这些内容基本上能够覆盖大多数命令行的使用场景。
1 Shell Scripting
上次课我们已经演示了如何在shell里运行程序,以及使用管道命令。
然而,在许多场景当中,我们希望能够运行一系列命令并且使用一些控制流命令,比如条件语句、循环等等。
Shell脚本的复杂度会提升一些,大多数Shell拥有它们专属的脚本语言,涵盖变量、控制流以及特有的语法。和其他脚本语言不同的是,shell脚本是专门为了运行shell相关的任务而优化过的。比如创建命令管道,将运行的结果保存在文件里,或者是从标准输入读入数据,都是shell脚本的基础操作,这也使得它比一些通用的脚本语言更加易用。这节课我们将会聚焦在bash脚本,因为它更加普遍。
在bash创建变量,使用语法foo=bar,将会创建一个变量$foo。需要注意foo = bar不会生效,因为它会将foo当成是要执行的程序,而=和bar当成是foo的参数。因为shell脚本是按照空格分隔参数的。这个特性在刚开始使用的时候会觉得很别扭,所以记得经常检查。
string可以使用单引号或双引号来表示,但它们不是等价的。以单引号分隔的字符串是纯字符,当中的变量不会被取值。而双引号的字符串可以。

和大多数编程语言一样,bash也支持控制流语法,比如if, case, while和for。同样,bash也有可以接收参数的函数,并且可以执行。下面是一个函数创建一个文件夹并且cd进入的例子。

这里的$1指的是脚本的第一个参数,和其他脚本语言不同,bash使用许多特殊的变量来代表参数、error代码和其他相关的变量。接下来列举其中常用的一些:
$0- 脚本的名称
$1 to $9 - 脚本的参数,$1是第一个参数,以此类推
$@- 所有的参数
$#- 参数的数量
$?- 上一个命令的返回结果(0代表正确,1代表错误)
$$- 当前脚本的运行PID(进程id)
!!- 上一个运行的命令,包括参数,比如我们运行某命令提示没有权限失败,我们想重试可以直接简写sudo !!
$_- 上一条命令的最后一个参数,如果你是在交互式的shell终端使用,你也可以使用快捷键Esc加上.或者是Alt+.。
命令通常使用STDOUT返回,错误通过STDERR,并且一个返回码提示错误是脚本友好的常用做法。返回码或者是退出时的状态是脚本/命令用来交互运行结果的一种方式。0通常意味着一切OK,除了0以外的值通常代表着出现了一些错误。

另外一个常用的语句是将一个命令的结果作为变量,这可以通过命令替换来实现。当你输入$( CMD )它会先运行CMD命令,获取命令的输出之后,将它立即当做是变量。
看个例子:
bash">#!/bin/bash
echo "Starting program at $(date)"
echo "Running program $0 with $# arguments with pid $$"
for file in "$@"; do
grep foobar "$file" > /dev/null 2> /dev/null
if [[ "$?" -ne 0 ]]; then
echo "File $file does not have any foobar,adding one"
echo "# foobar" >> "$file"
fi
done
grep foobar "$file" > /dev/null 2> /dev/null这行代码当中细节有些多,展开来说一说。
首先是grep语句,这是过滤语句,意思是从$file文件当中过滤包含foobar的文本。正常grep找到之后的结果会输出到stdout,这里我们给它重定向到了/dev/null,这是Linux系统中的一个特殊文件,输入的数据都会丢弃。
如果 grep语句没有找到一条吻合的文本,那么会生成一个错误码。为了不让错误码影响程序的运行,我们把错误码也重定向到了/dev/null,错误码重定向使用的是2>
if [[ "$?" -ne 0 ]]:$?代表着返回码,如果不等于(not equal,ne)0,就执行echo。双方括号代表着比较[[]]
通配符?*
当你想要匹配任意字符时,你可以使用?或者*来代替一个或任意多个字符。比如我们有foo, foo1, foo2, foo10, bar这几个文件。命令rm foo?将会删除foo1, foo2(一个问号代表1个通配符)而rm foo*将会删除除了bar之外所有的foo开头文件。
例如:删除所有1.sh结尾的文件
bash">find . -name "*1.sh" -exec rm {} \;
花括号{}
当你的命令拥有一系列共同的单词时,你可以使用花括号来扩展。
我想创建sh文件,通过{}{}之间的笛卡尔积映射即可实现。
bash">touch {a,b}_{1,2}.sh
2 Shell 工具
2.1 命令说明/帮助
man--helptldr:给出使用命令的例子

2.2查找
1 查找文件
find:递归的返回匹配的文件

进阶:可以在find的结果上进一步操作。比如查找后批量删除这些文件。

虽然find工具很好用, 但有时候它的语法很难记住。比如说fd是一个简单快速,并且好用的find替代品。它提供许多默认的功能,比如说彩色输出、正则表达式匹配以及支持unicode。它拥有一个我个人认为更直观的语法,比如说当你想要找到一个模式PATTERN,你可以仅仅输入fd PATTERN。
2 查找命令
which查找命令所在的地址
bash">which rm
3 查找代码
grep
通过文件名查找文件非常方便,但也经常会希望根据文件中的内容进行查找。
比如我们可能会希望搜索所有包含了某个特定pattern的文件,以及这些pattern出现的位置。为了实现这一点,大多数类Unix系统提供了grep工具,它可以从输入文本中进行模式匹配。

但grep -R也有很多改进的地方,比如说忽略.git文件夹,使用多核CPU等等。有很多grep的替代工具,比如说ack, ag和rg。这些工具都非常好用,并且功能非常接近。我个人目前使用ripgrep(rg),它运行非常快速,并且很直观。

4 查找shell历史命令
history:可以让你看到你shell中历史上所有的命令,它会通过标准输出来展示所有的记录。如果我们想要搜索一些特定的命令,可以使用grep来查找特定的模式。history 5 | grep find将会输出包括find关键字最近的5个命令。
Ctrl + R:搜索你的历史记录。在按下Ctrl + R之后,你可以输入你想要搜索的命令的关键字。当你持续按下Ctrl + R,它将会在匹配的多条记录中循环查找。这也可以在zsh中设置成使用上下箭头。
3 习题
-
阅读man ls并且写一个ls命令,使得它完成以下格式:
- 包括所有文件,包括隐藏文件
a - 将文件大小以人们可阅读的形式展示比如(454M 而不是 454279954)
h - 文件按照最近访问时间排序
t - 输出彩色结果
--color
一个参考输出应该是这样的:

- 包括所有文件,包括隐藏文件
答案:
bash">ls --laht --color
- 写一个
bash函数macro和polo。当你运行macro时,你当前工作的路径应当以某种方式被保存。当你运行polo时,无论你处在什么路径下,polo都会cd回你之前运行macro的地方。为了方便debug,你可以将代码写在macro.sh中,通过source macro.sh载入代码.
答案:
逻辑不难想到,当我们执行macro时,我们需要保存下当前路径。由于当函数执行结束,函数中的变量即销毁,所以我们要把它export成全局变量。
在polo函数当中,直接cd到导出的全局变量即可。
bash">macro() {
export cachepath=$(pwd)
}
polo() {
cd $cachepath
}
- 假设你有一个命令很少失败,为了
debug,你需要捕获它的输出,但可能会花很多时间才能重现失败。写一个bash函数,它会重复执行下列脚本,直到失败,并且捕获它的标准输出以及错误流写入文件,并在结束时打印出来。如果你还能汇报一共执行了多少次可以获得额外分数奖励.
bash"> #!/usr/bin/env bash
n=$(( RANDOM % 100 ))
if [[ n -eq 42 ]]; then
echo "Something went wrong"
>&2 echo "The error was using magic numbers"
exit 1
fi
echo "Everything went according to plan"
答案:
bash">function func() {
cnt=1
./random.sh > output.txt 2> error.txt
while [[ $? -eq 0 ]]
do
(( cnt++ ))
./random.sh > output.txt 2> error.txt
done
cat error.txt
echo "$cnt"
}
- 我们上课的时候说过find命令的exec参数非常强大,可以批量搜索处理文件。然而,如果我们想要对所有文件做一些操作,比如说创建一个zip文件,我们该怎么操作呢?就像你看到的一样,命令从参数和STDIN接收输入,当使用管道时,我们将STDOUT和STDIN结合起来。但一些命令,比如tar从参数获取数据。为了打通这两者之间的信息沟通,有一个叫做xargs的命令,可以使用STDIN当做参数来运行命令。比如ls | xargs rm将会删除当前路径下所有文件。你的任务是写一个命令,它能够递归查找当前路径下所有HTML文件,并且给它们创建zip压缩包。注意:即使文件名中包含空格,你的命令也依然需要生效。(提示,查看xargs``-dflag)。如果你是macOS,需要注意,find和GNU coreutils中的不同。你可以使用find -print0以及xargs中的-0flag。作为一个mac用户,你也需要意识到,mac安装命令行工具的方法和GNU不同,你可以使用brew安装GNU版本
答案:
bash">find . -path "*.html" -type f -print0 | xargs -0 zip archieve.zip
- (进阶)写一个命令或脚本来递归式地查找当前路径下最经常访问的文件。另外,你可以根据最近访问时间列出所有的文件吗?
答案:
bash">find . -type f -print0 | xargs -0 ls -lht;